作为 iOS 开发者,我们都非常熟悉 Objective-C 的消息派发机制,围绕着这个机制也诞生了一系列“黑(miàn)魔(shì)法(tí)”。而到了 Swift 这边我们似乎还都在吃 OC 的老本,继续用着 @objc 来搞事。其实 Swift 在方法派发这件事上也做了很多底层的改变和优化,本文将以 Protocol 的视角来剖析一下 Swift 中的方法派发机制。
回顾一下 objc_msgSend
Objective-C 中的万物皆对象,不管是具体的类(如 NSObject *)还是 id,都具有类似的内存结构,即:
union isa_t {
isa_t() { }
isa_t(uintptr_t value) : bits(value) { }
Class cls;
uintptr_t bits;
#if defined(ISA_BITFIELD)
struct {
ISA_BITFIELD; // defined in isa.h
};
#endif
};
struct objc_object {
private:
isa_t isa;
// ivars...
};
而常规的方法调用(除 objc_direct 外)无一例外会走 objc_msgSend 的消息派发流程。因此在 Objective-C 中,是否为 protocol 不会决定方法派发的方式,只会影响编译时的一系列静态检查。
关于 Objective-C 的消息派发机制本文就不过度展开了,有兴趣大家可以自己研究一下。
C++ 的虚方法及 vtable
在回到 Swift 之前我们再来看看另一个语言 C++ 是如何做方法派发的,这对理解 Swift 的机制也会有一定帮助和参考意义。
C++ 对象的内存布局相比 Objective-C 对象的更加灵活,根据基类和成员方法的不同会有多种形态。当一个类为“标准布局类型”(StandardLayoutType)时,其内存布局与 C 中 struct 的内存布局一致。而当我们给类增加一个虚方法时,其内存布局就会发生变化,即在最前面增加了 vtable 指针。
与 Objective-C 有一定区别的是,vtable 指针的赋值时机和 OC 对象 isa 的赋值时机不同。由于 OC 对象的构造是显式二段式,也就是 alloc 与 init 可以分开进行,一个对象在 alloc 之后就已经具有类型信息了(即 isa 已被初始化)。而 C++ 对象的构造是空间分配和初始化一体的,并且 C++ 支持 placement new 特性来将一个对象初始化到一个已经分配好的内存空间上,因此 C++ 在构造器中对 vtable 指针进行赋值。
我们可以反编译下面的这个代码片段来验证这个过程:
class A {
public:
virtual void foo() { }
};
int main() {
A *a = new A;
return 0;
}
反编译结果如下:
main:
push rbp
mov rbp, rsp
sub rsp, 32
mov dword ptr [rbp - 4], 0
; A *a = new A;
mov edi, 8
call operator new(unsigned long)
mov rdi, rax
mov qword pttr [rbp - 24], rax
call A::A() ; [base object constructor]
; ...
可以看到对象构造的两段过程,operator new 仅分配空间,接下来直接调用构造器:
A::A():
push rbp
mov rbp, rsp
movabs rax, offset vtable for A
add rax, 16
mov qword ptr [rbp - 8], rdi
mov rcx, qword ptr [rbp - 8]
mov qword ptr [rcx], rax
pop rbp
ret
此时 rdi 寄存器为 this 指针(即对象的地址),vtable 指针经过偏移后被赋给对象的首部空间。
接下来来看方法派发的实现,我们直接反编译下面这段代码:
class A {
public:
virtual void foo() = 0;
};
class B {
public:
virtual void bar() = 0;
};
class C : public A, public B {
public:
virtual void foo() { }
virtual void bar() { }
};
int main() {
C *c = new C;
c->bar(); // 主要关注这里
return 0;
}
反编译结果如下:
main:
push rbp
mov rbp, rsp
sub rsp, 32
mov dword ptr [rbp - 4], 0
mov edi, 16
call operator new(unsigned long)
mov rdi, rax
mov qword ptr [rbp - 24], rax
call C::C() [base object constructor]
mov rax, qword ptr [rbp - 24]
mov qword ptr [rbp - 16], rax
mov rcx, qword ptr [rbp - 16] ; rcx 现在是 c 的指针
mov rdx, qword ptr [rcx] ; rdx 现在是 vtable 指针
mov rdi, rcx
call qword ptr [rdx + 8] ; 调用 (vtable + 8) 地址指向的函数
xor eax, eax
add rsp, 32
pop rbp
ret
可以看到一次查表的过程,由于类 C 中包含虚方法,方法调用不能采用静态派发方式(为了实现多态),但与 Objective-C 不同的是这个查表过程非常简单,其实就是个数组访问的操作,因此它的性能也会比 Objective-C 的消息派发(查 cache / 遍历 method list)快上很多倍。
但假如这里我们稍微变换一下代码:
int main() {
B *b = new C; // 变量类型从 C 改成了基类 B
b->bar();
return 0;
}
再看反编译结果:
main:
push rbp
mov rbp, rsp
sub rsp, 32
mov dword ptr [rbp - 4], 0
mov edi, 16
call operator new(unsigned long)
mov rdi, rax
mov qword ptr [rbp - 24], rax
call C::C() [base object constructor]
xor ecx, ecx
mov eax, ecx
mov rdx, qword ptr [rbp - 24]
cmp rdx, 0
mov qword ptr [rbp - 32], rax
je .LBB0_2 ; 这里有个判空保护,我们直接忽略这行
mov rax, qword ptr [rbp - 24]
add rax, 8 ; this 指针被偏移了 8,赋给 rax(记变量 b)
mov qword ptr [rbp - 32], rax
.LBB0_2:
mov rax, qword ptr [rbp - 32]
mov qword ptr [rbp - 16], rax
mov rax, qword ptr [rbp - 16] ; rax 现在等于变量 b 的值
mov rcx, qword ptr [rax] ; 到这里就回到与上个例子相同的查表逻辑
mov rdi, rax
call qword ptr [rcx]
xor eax, eax
add rsp, 32
pop rbp
ret
改变了一下变量的类型,汇编代码竟然有这么大的变化。其实到后面大家就会发现 C++ 与 Swift 类似,会根据代码上下文的不同来改变生成的代码。原因也很简单,我们先来看 C++ 这个现象背后的原理。首先看一下类型 C 的构造器汇编代码:
C::C() [base object constructor]:
push rbp
mov rbp, rsp
sub rsp, 16
mov qword ptr [rbp - 8], rdi
mov rax, qword ptr [rbp - 8]
mov rcx, rax
mov rdi, rcx
mov qword ptr [rbp - 16], rax
call A::A() [base object constructor] ; 调用 A 的构造器
mov rax, qword ptr [rbp - 16]
add rax, 8
mov rdi, rax
call B::B() [base object constructor] ; 调用 B 的构造器
movabs rax, offset vtable for C
mov rcx, rax
add rcx, 48
add rax, 16
mov rdx, qword ptr [rbp - 16]
mov qword ptr [rdx], rax
mov qword ptr [rdx + 8], rcx
add rsp, 16
pop rbp
ret
由于每个类的构造器都会为那个类型设置 vtable 指针,因此类 C 的对象中会存在 2 个 vtable 指针(第一个被 C 自己的 vtable 指针覆盖了)!最开始的那里例子中,我们调用的是 C::bar 方法,由于接收类型是 C,因此查的也是 C 的 vtable,其内容如下:
vtable for C:
.quad 0
.quad typeinfo for C
.quad C::foo()
.quad C::bar()
.quad -8
.quad typeinfo for C
.quad non-virtual thunk to C::bar()
C 继承了 A、B,因此 vtable for C 是会向下兼容类 A 的 vtable 的(即把 C* 的值赋给 A* 变量与 C* 的值赋给 C* 变量是相同的)。这个特性可以使得一个固定方法在 vtable 中的 index 是固定的。比如调用 C::bar,查找 vtable 下标就是 1,不管其真实类型是什么。
当我们将 C* 的值赋给 B* 的变量时,由于两者的 vtable 结构不兼容(很显然,vtable for C 和 vtable for B 的第一个函数指针不同),我们就不能不做任何处理地把原地址赋值过去,而是要偏移到兼容 vtable for B 的第二个 vtable 地址。这时当我们调用 B::bar 的时候,根据 vtable 内容,就会调用到 non-virtual thunk to C::bar() 函数中。
这里画了一张图,方便大家理解:
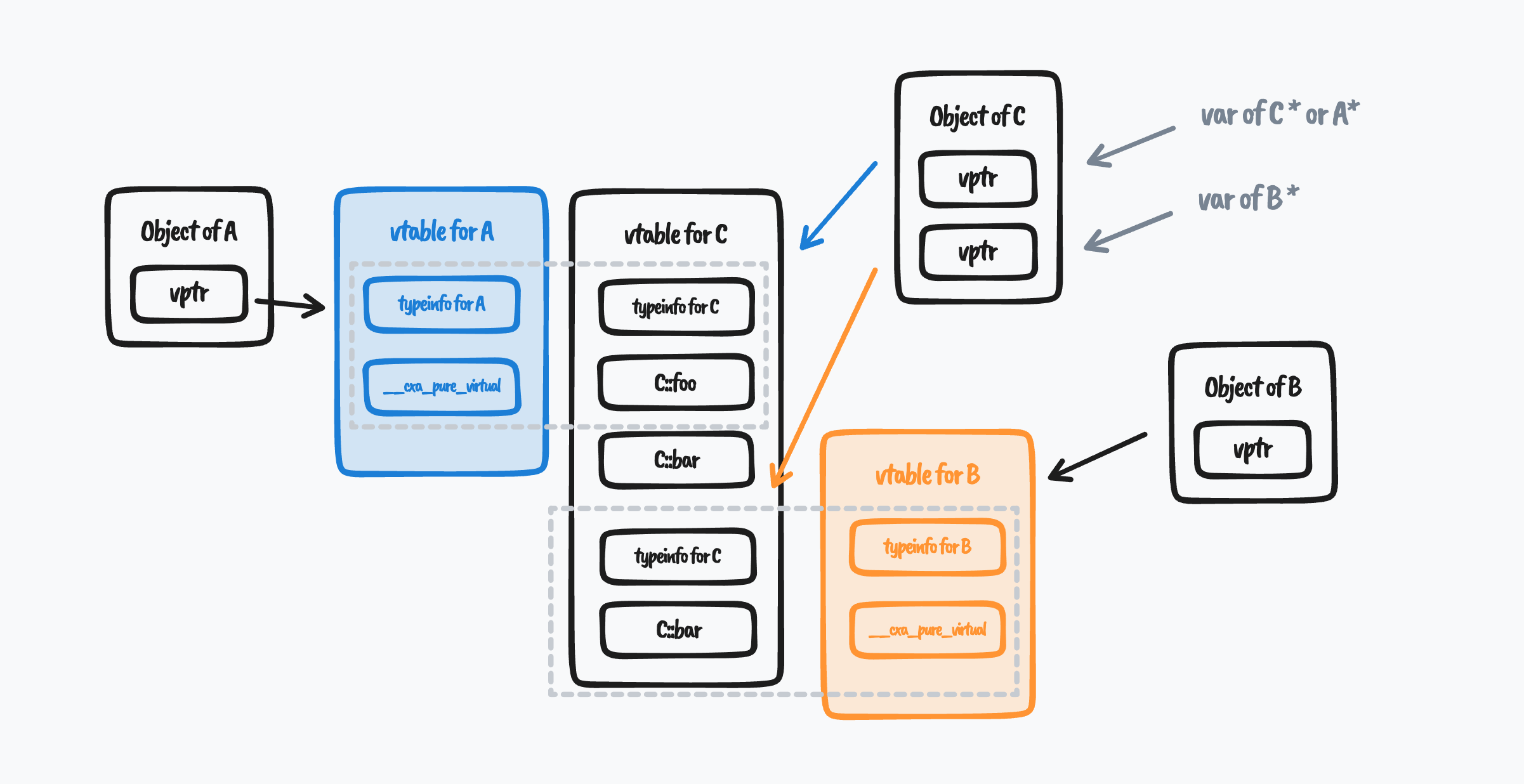
thunk 到底是什么?
看到这里你可能会发现了,这咋 vtable for B 的内容和 vtable for C 的还不一样呢?虽然我们的目的都是调用 C::bar,但是还记得上文说的对象指针偏移吗?由于 C* 赋给 B* 变量时指针发生了偏移,C::bar 拿到的 this 指针就不正确了。所以我们这里不能直接调用 C::bar,而是要先调用一个“跳板”函数,这就是所谓的 thunk。大家记住这个东西,后面我们分析 Swift 时还会遇到哦。 我们来看一下这个 thunk 所做的事情:
non-virtual thunk to C::bar():
push rbp
mov rbp, rsp
mov qword ptr [rbp - 8], rdi
mov rax, qword ptr [rbp - 8]
add rax, -8
mov rdi, rax ; 其实只是对 this 做了一次偏移
pop rbp
jmp C::bar() ; 尾递归风格调用,不会产生新栈帧
所以 thunk 基本上就是对入参(通常是 this)进行一些调整,然后调用真正的函数继续执行。
Back to Swift
上面我们简单回顾了一下 Objective-C 和 C++ 的方法派发机制,不是很完整,但相信大家能够大致理解其中的思路了。有了这些前置知识之后再来分析 Swift 的方法派发就会容易得多。
但是在正式开始之前我们还是要再认识两个中间语言:SIL、LLVM IR。不像 C++,Swift 的反编译结果比较晦涩,原因一方面是 Swift ABI 结构相比 C++ 会更复杂一些;另一方面是 SIL 的存在会对 Swift 源码做一次去抽象(desugar、lowering),之后生成的 LLVM IR 又会对类 C 的操作做一次优化,最后得到的代码就比较难看出原貌了。因此本文分析 Swift 的时候不去看反汇编代码,而主要去看 LLVM IR,因为在这一层仍然能保留很多内存布局的信息,各种操作相比机器码也更易于理解。关于 SIL 和 LLVM IR,本文不过多展开,大家可以在阅读文章时找到对应的文档自行参考。
通过静态派发初识 SIL、LLVM IR
第一个例子我们先来看看 Swift 中的静态派发,考虑下面的代码:
protocol SomeRegularProtocol {
func methodA(_ x: Int) -> Int
}
struct SomeImpl: SomeRegularProtocol {
let data: Int
func methodA(_ x: Int) -> Int {
return data + x
}
}
let impl = SomeImpl(data: 1024)
impl.methodA(42)
由于 struct 不能继承,使用时均是值类型,因此调用的方法地址一定是确定的,我们来分别看看 SIL 和 LLVM IR:
// SIL
// main
sil @main : $@convention(c) (Int32, UnsafeMutablePointer<Optional<UnsafeMutablePointer<Int8>>>) -> Int32 {
bb0(%0 : $Int32, %1 : $UnsafeMutablePointer<Optional<UnsafeMutablePointer<Int8>>>):
alloc_global @$s4main4implAA8SomeImplVvp // id: %2
%3 = global_addr @$s4main4implAA8SomeImplVvp : $*SomeImpl // users: %10, %9
%4 = metatype $@thin SomeImpl.Type // user: %8
%5 = integer_literal $Builtin.Int64, 1024 // user: %6
%6 = struct $Int (%5 : $Builtin.Int64) // user: %8
// function_ref SomeImpl.init(data:)
%7 = function_ref @$s4main8SomeImplV4dataACSi_tcfC : $@convention(method) (Int, @thin SomeImpl.Type) -> SomeImpl // user: %8
%8 = apply %7(%6, %4) : $@convention(method) (Int, @thin SomeImpl.Type) -> SomeImpl // user: %9
store %8 to %3 : $*SomeImpl // id: %9
%10 = load %3 : $*SomeImpl // user: %14
%11 = integer_literal $Builtin.Int64, 42 // user: %12
%12 = struct $Int (%11 : $Builtin.Int64) // user: %14
// >>>> 这里要调用方法了 <<<<
// function_ref SomeImpl.methodA(_:)
%13 = function_ref @$s4main8SomeImplV7methodAyS2iF : $@convention(method) (Int, SomeImpl) -> Int // user: %14
%14 = apply %13(%12, %10) : $@convention(method) (Int, SomeImpl) -> Int
%15 = integer_literal $Builtin.Int32, 0 // user: %16
%16 = struct $Int32 (%15 : $Builtin.Int32) // user: %17
return %16 : $Int32 // id: %17
} // end sil function 'main'
从 SIL 上就能看出对 SomeImpl.methodA(_:) 的调用就是直接拿到对应方法的函数指针,然后直接调用过去。这里提一下 @convention(method) 这个标注,它会指定一个方法的调用规约(Calling Convention),这里 method 其实与常规的 System V ABI 差不多,只不过规定了第一个参数是 self 指针。但需要注意的是,SIL 里体现的并不一定是真实的操作,到 LLVM IR 这一层之前仍然会有很多优化,我们来看看上面代码到 LLVM IR 后的结果:
define i32 @main(i32 %0, i8** %1) #0 {
entry:
%2 = bitcast i8** %1 to i8*
%3 = call swiftcc i64 @"$s4main8SomeImplV4dataACSi_tcfC"(i64 1024)
store i64 %3, i64* getelementptr inbounds (%T4main8SomeImplV, %T4main8SomeImplV* @"$s4main4implAA8SomeImplVvp", i32 0, i32 0, i32 0), align 8
%4 = load i64, i64* getelementptr inbounds (%T4main8SomeImplV, %T4main8SomeImplV* @"$s4main4implAA8SomeImplVvp", i32 0, i32 0, i32 0), align 8
// 直接调用对应方法,但注意入参
%5 = call swiftcc i64 @"$s4main8SomeImplV7methodAyS2iF"(i64 42, i64 %4)
ret i32 0
}
可以看到 LLVM IR 的代码比 SIL 简单了很多,很多无用操作会被优化掉。同时我们会发现 SomeImpl.methodA(_:) 方法的入参发生了变化,第二个参数是一个 Int,这也是编译期做的优化,因为这个方法并不需要完整的结构体内容,仅传入需要的数据可以减少拷贝开销。
Protocol 方法调用的实现原理
上面的代码里我们声明了一个 protocol,在正常使用结构体的时候我们没有看到任何动态派发的过程,那我们用 protocol 的方式调用一下看看,首先修改一下代码:
// ...
func useRegularProtocol(_ p: SomeRegularProtocol) {
let _ = p.methodA(42)
}
let impl = SomeImpl(data: 1024)
useRegularProtocol(impl)
然后我们来看一下 SIL:
// main
sil @main : $@convention(c) (Int32, UnsafeMutablePointer<Optional<UnsafeMutablePointer<Int8>>>) -> Int32 {
bb0(%0 : $Int32, %1 : $UnsafeMutablePointer<Optional<UnsafeMutablePointer<Int8>>>):
alloc_global @$s4main4implAA8SomeImplVvp // id: %2
%3 = global_addr @$s4main4implAA8SomeImplVvp : $*SomeImpl // users: %11, %9
%4 = metatype $@thin SomeImpl.Type // user: %8
%5 = integer_literal $Builtin.Int64, 1024 // user: %6
%6 = struct $Int (%5 : $Builtin.Int64) // user: %8
// function_ref SomeImpl.init(data:)
%7 = function_ref @$s4main8SomeImplV4dataACSi_tcfC : $@convention(method) (Int, @thin SomeImpl.Type) -> SomeImpl // user: %8
%8 = apply %7(%6, %4) : $@convention(method) (Int, @thin SomeImpl.Type) -> SomeImpl // user: %9
store %8 to %3 : $*SomeImpl // id: %9
// 以上都没什么区别
// 这里开辟了一个存放 protocol 变量的空间
%10 = alloc_stack $SomeRegularProtocol // users: %17, %16, %15, %12
%11 = load %3 : $*SomeImpl // user: %13
// 做了一个奇怪操作,一会着重看一下
%12 = init_existential_addr %10 : $*SomeRegularProtocol, $SomeImpl // user: %13
store %11 to %12 : $*SomeImpl // id: %13
// function_ref useRegularProtocol(_:)
// 直接调用我们的 useRegularProtocol 方法
%14 = function_ref @$s4main18useRegularProtocolyyAA04SomecD0_pF : $@convention(thin) (@in_guaranteed SomeRegularProtocol) -> () // user: %15
%15 = apply %14(%10) : $@convention(thin) (@in_guaranteed SomeRegularProtocol) -> ()
destroy_addr %10 : $*SomeRegularProtocol // id: %16
dealloc_stack %10 : $*SomeRegularProtocol // id: %17
%18 = integer_literal $Builtin.Int32, 0 // user: %19
%19 = struct $Int32 (%18 : $Builtin.Int32) // user: %20
return %19 : $Int32 // id: %20
} // end sil function 'main'
上面我们遇到了一个新指令:init_existential_addr。不知道是什么,我们查一下 SIL 文档:
Partially initializes the memory referenced by
%0with an existential container prepared to contain a value of type$T. The result of the instruction is an address referencing the storage for the contained value, which remains uninitialized. The contained value must bestore-d orcopy_addr-ed to in order for the existential value to be fully initialized. If the existential container needs to be destroyed while the contained value is uninitialized, deinit_existential_addr must be used to do so. A fully initialized existential container can be destroyed with destroy_addr as usual. It is undefined behavior to destroy_addr a partially-initialized existential container.
Existential Container
这里又出现了一个新概念:Existential Container。这个概念大家如果熟悉 Swift 的话应该或多或少听说过,简单来讲它就是一个存放任意类型的变量,你可以把它理解为 Any。为了做到这一点,Swift 在运行时需要知道这个变量的存储数据(结构体、类本身)、类型、一系列特征值。这三要素缺一不可,存储数据好理解,大家可能会问为什么需要类型信息呢?因为 Swift 的 struct 是非常朴素的,它在内存布局中完全无法体现类型信息,如果不是编译时插入了什么上下文信息,我们在运行时拿到一个指向 struct 的地址是不能解析出它的类型名等信息的。而后面的一系列特征值则是我们通常讲的 witness tables,分为 protocol witness table 和 value witness table。他们在 protocol 方法派发过程中起到了至关重要的作用。
Swift 的 ABI 稳定后 Existential Container 的内存布局不会发生变化,可以用 C 代码表示为:
struct OpaqueExistentialContainer {
void *fixedSizeBuffer[3];
Metadata *type;
WitnessTable *witnessTables[NUM_WITNESS_TABLES];
};
其中 fixedSizeBuffer 存放了 struct 的数据,如果 3 * 8 = 24 个字节放不下会转移到堆内存去,这个机制与 C++ 的 std::string 实现很像,属于 SBO 优化。
另外 Existential Container 还有一个变种版本,如果确定一个 protocol 一定是 class 类型时,它的内存布局会变成:
struct ClassExistentialContainer {
HeapObject *value;
WitnessTable *witnessTables[NUM_WITNESS_TABLES];
};
因为 class 对象的内存布局里一定有 Metadata 信息。
到这里其实我们就可以看一下上面那段代码转成 LLVM IR 的结果了(代码很长,你忍一下):
define i32 @main(i32 %0, i8** %1) #0 {
entry:
// 这里已经为 protocol 变量分配栈空间了
%2 = alloca %T4main19SomeRegularProtocolP, align 8
%3 = bitcast i8** %1 to i8*
%4 = call swiftcc i64 @"$s4main8SomeImplV4dataACSi_tcfC"(i64 1024)
store i64 %4, i64* getelementptr inbounds (%T4main8SomeImplV, %T4main8SomeImplV* @"$s4main4implAA8SomeImplVvp", i32 0, i32 0, i32 0), align 8
// 开始为 Existential Container 赋值
%5 = bitcast %T4main19SomeRegularProtocolP* %2 to i8*
call void @llvm.lifetime.start.p0i8(i64 40, i8* %5)
// 注意:%6 是 SomeImpl.data 的值,这里没有立即使用
%6 = load i64, i64* getelementptr inbounds (%T4main8SomeImplV, %T4main8SomeImplV* @"$s4main4implAA8SomeImplVvp", i32 0, i32 0, i32 0), align 8
// %7 是指向 type 的地址,紧接着的 store 指令为其赋了 SomeImpl 的 Metadata
%7 = getelementptr inbounds %T4main19SomeRegularProtocolP, %T4main19SomeRegularProtocolP* %2, i32 0, i32 1
store %swift.type* bitcast (i64* getelementptr inbounds (<{ i8**, i64, <{ i32, i32, i32, i32, i32, i32, i32 }>*, i32, [4 x i8] }>, <{ i8**, i64, <{ i32, i32, i32, i32, i32, i32, i32 }>*, i32, [4 x i8] }>* @"$s4main8SomeImplVMf", i32 0, i32 1) to %swift.type*), %swift.type** %7, align 8
// %8 是 witnessTables 指向的地址,紧接着的 store 指令为其赋值
%8 = getelementptr inbounds %T4main19SomeRegularProtocolP, %T4main19SomeRegularProtocolP* %2, i32 0, i32 2
store i8** getelementptr inbounds ([2 x i8*], [2 x i8*]* @"$s4main8SomeImplVAA0B15RegularProtocolAAWP", i32 0, i32 0), i8*** %8, align 8
// 开始为 fixedSizeBuffer 赋值,由于空间足够,这里采用 inline 模式
%10 = getelementptr inbounds %T4main19SomeRegularProtocolP, %T4main19SomeRegularProtocolP* %2, i32 0, i32 0
%11 = bitcast [24 x i8]* %10 to %T4main8SomeImplV*
%.data = getelementptr inbounds %T4main8SomeImplV, %T4main8SomeImplV* %11, i32 0, i32 0
%.data._value = getelementptr inbounds %TSi, %TSi* %.data, i32 0, i32 0
store i64 %6, i64* %.data._value, align 8
// 赋值完毕
// 直接调用 useRegularProtocol 方法
call swiftcc void @"$s4main18useRegularProtocolyyAA04SomecD0_pF"(%T4main19SomeRegularProtocolP* noalias nocapture dereferenceable(40) %2)
%12 = bitcast %T4main19SomeRegularProtocolP* %2 to %__opaque_existential_type_1*
call void @__swift_destroy_boxed_opaque_existential_1(%__opaque_existential_type_1* %12) #3
%13 = bitcast %T4main19SomeRegularProtocolP* %2 to i8*
call void @llvm.lifetime.end.p0i8(i64 40, i8* %13)
ret i32 0
}
上面的代码就是 init_existential_addr 所表示的操作了,基本上跟我们的预想一样。到这里我们会发现,Swift 并不会像 C++ 那样,由于一个类定义了虚方法(实现 protocol 方法也算虚方法了),就为它立即生成一个 vtable 并伴随对象生命周期。Swift 将这个过程 defer 到 casting 的时机了,也就是说只有当我们把 SomeImpl 当作 protocol 或 Any 去用的时候才会生成对应的 witness tables,否则这部分开销就不需要。并且生成的 witness tables 不像 C++ 的 vtable 包含了所有的方法,而只会包含对应 protocol 需要的方法。如果你去 demangle pwt 的符号名,会得到 protocol witness table for main.SomeImpl : main.SomeRegularProtocol in main,也就是说这个 pwt 就是 X 类型实现 Y 协议专用的。
Value Witness Table
除了 pwt 以外还存在着 vwt,前者与 protocol 相关,而后者则与任何 Existential Container 都有关。想象一下,当一个 Any 变量退出作用域时会发生什么。
对于引用类型而言,退出作用域需要减少引用计数;而对于 struct 而言这里就要分情况讨论一下,有引用类型成员的 struct 需要对这些成员做引用计数减少,没有引用类型成员的 struct 则只需要释放内存空间即可。一个 Any 变量如何确定自己执行释放、拷贝等操作时应该做什么,这就取决于 Value Withness Table。
这里我们用一个简单的例子展示一下 vwt 的使用场景,就不过多展开了:
struct SomeImpl: SomeRegularProtocol {
let obj = NSObject()
}
func test() {
let p: SomeRegularProtocol = SomeImpl(data: 42)
}
IR 如下:
define hidden swiftcc void @"$s4main4testyyF"() #0 {
entry:
%0 = alloca %T4main19SomeRegularProtocolP, align 8
%1 = bitcast %T4main19SomeRegularProtocolP* %0 to i8*
// 此处省略 10 多行...
%10 = bitcast %T4main19SomeRegularProtocolP* %0 to %__opaque_existential_type_1*
call void @__swift_destroy_boxed_opaque_existential_1(%__opaque_existential_type_1* %10) #2
%11 = bitcast %T4main19SomeRegularProtocolP* %0 to i8*
call void @llvm.lifetime.end.p0i8(i64 40, i8* %11)
ret void
}
可以看到编译器在作用域退出时生成了 __swift_destroy_boxed_opaque_existential_1 调用,这个函数实际也是编译器合成的一个行数,我们可以看到它对应的代码:
; Function Attrs: noinline nounwind
define linkonce_odr hidden void @__swift_destroy_boxed_opaque_existential_1(%__opaque_existential_type_1* %0) #9 {
entry:
// %1 是类型的 Metadata
%1 = getelementptr inbounds %__opaque_existential_type_1, %__opaque_existential_type_1* %0, i32 0, i32 1
%2 = load %swift.type*, %swift.type** %1, align 8
%3 = getelementptr inbounds %__opaque_existential_type_1, %__opaque_existential_type_1* %0, i32 0, i32 0
%4 = bitcast %swift.type* %2 to i8***
%5 = getelementptr inbounds i8**, i8*** %4, i64 -1
// 从 Metadata 里取出 vwt
%.valueWitnesses = load i8**, i8*** %5, align 8, !invariant.load !48, !dereferenceable !49
%6 = bitcast i8** %.valueWitnesses to %swift.vwtable*
%7 = getelementptr inbounds %swift.vwtable, %swift.vwtable* %6, i32 0, i32 10
// 从 vwt 中取出 flags 字段(详见下文)
%flags = load i32, i32* %7, align 8, !invariant.load !48
%8 = and i32 %flags, 131072
%flags.isInline = icmp eq i32 %8, 0
br i1 %flags.isInline, label %inline, label %outline
// 对象的存储数据以 inline 形式存放在 existential container 的 buffer 里
inline: ; preds = %entry
%9 = bitcast [24 x i8]* %3 to %swift.opaque*
%10 = bitcast %swift.type* %2 to i8***
%11 = getelementptr inbounds i8**, i8*** %10, i64 -1
%.valueWitnesses1 = load i8**, i8*** %11, align 8, !invariant.load !48, !dereferenceable !49
// 从 vwt 中取出 destroy 操作的函数地址
%12 = getelementptr inbounds i8*, i8** %.valueWitnesses1, i32 1
%13 = load i8*, i8** %12, align 8, !invariant.load !48
%destroy = bitcast i8* %13 to void (%swift.opaque*, %swift.type*)*
// 调用 destroy 函数
call void %destroy(%swift.opaque* noalias %9, %swift.type* %2) #2
ret void
// 对象以 outline 形式分配在堆上,直接走引用计数 release 流程
outline: ; preds = %entry
%14 = bitcast [24 x i8]* %3 to %swift.refcounted**
%15 = load %swift.refcounted*, %swift.refcounted** %14, align 8
call void @swift_release(%swift.refcounted* %15) #2
ret void
}
上面我们看到的 vwt 的数据结构在 Swift ABI 源码中均有体现,大家可以主要参考这个文件:Metadata.h:334
顺便我们再看一下上面这个例子 vwt 里的函数吧,SomeImpl 的 vwt 内容如下:
@"$s4main8SomeImplVWV" = internal constant %swift.vwtable {
i8* bitcast (%swift.opaque* ([24 x i8]*, [24 x i8]*, %swift.type*)* @"$s4main8SomeImplVwCP" to i8*),
i8* bitcast (void (%swift.opaque*, %swift.type*)* @"$s4main8SomeImplVwxx" to i8*),
i8* bitcast (%swift.opaque* (%swift.opaque*, %swift.opaque*, %swift.type*)* @"$s4main8SomeImplVwcp" to i8*),
i8* bitcast (%swift.opaque* (%swift.opaque*, %swift.opaque*, %swift.type*)* @"$s4main8SomeImplVwca" to i8*),
i8* bitcast (i8* (i8*, i8*, %swift.type*)* @__swift_memcpy16_8 to i8*),
i8* bitcast (%swift.opaque* (%swift.opaque*, %swift.opaque*, %swift.type*)* @"$s4main8SomeImplVwta" to i8*),
i8* bitcast (i32 (%swift.opaque*, i32, %swift.type*)* @"$s4main8SomeImplVwet" to i8*),
i8* bitcast (void (%swift.opaque*, i32, i32, %swift.type*)* @"$s4main8SomeImplVwst" to i8*),
i64 16, i64 16, i32 65543, i32 2147483647
}, align 8
其中 destroy 对应的函数是 s4main8SomeImplVwxx,其内容如下:
; Function Attrs: nounwind
define internal void @"$s4main8SomeImplVwxx"(%swift.opaque* noalias %object, %swift.type* %SomeImpl) #10 {
entry:
%0 = bitcast %swift.opaque* %object to %T4main8SomeImplV*
%.obj = getelementptr inbounds %T4main8SomeImplV, %T4main8SomeImplV* %0, i32 0, i32 1
%toDestroy = load %TSo8NSObjectC*, %TSo8NSObjectC** %.obj, align 8
%1 = bitcast %TSo8NSObjectC* %toDestroy to i8*
call void @llvm.objc.release(i8* %1)
ret void
}
可以说是非常浅显易懂了。
thunk?
大家一定在调用栈中见过 protocol witness for X in conformance Y 这个奇怪方法,为什么有了 pwt 还需要一个跳板函数来调用真实的函数呢?

可以回想一下上文中提到的 C++ thunk 和 SIL 优化。回到 “通过静态派发初识 SIL、LLVM IR” 这一小节,Swift 的 struct 方法会有个成员内联的优化,也就是说方法参数中不会传入完整的 struct 对象,而只会传入所需要使用的成员。然而 protocol 调用时并不了解这一细节,调用方仍然需要将完整的 self 指针作为一个参数传入。这里编译器有两个选择:
- 生成两份方法代码,分别适配直接调用和 protocol 调用
- 生成跳板函数,在跳板函数中提取成员后调用原方法
显然第二种方法更为高效。
实际上 thunk 函数的作用还有很多,大家开发 OC 日常可能会用到的 Method Swizzling 也会用到类似 thunk 的技术,如果有兴趣也可以深入研究一下,还是非常有意思的。
总结
本文从 Objective-C、C++ 切入,以 SIL、LLVM IR 为“抓手”详细分析了 Swift Protocol 的方法派发原理,从中我们可以发现语言之间的很多共性,例如通过 thunk 来适配不同的调用方,通过函数表实现多态等。现代的很多编程语言实际上存在非常多相似的实现思路,比如 Golang 的 interface{} 也是用了跟 Swift Existential Container 一样的结构,只不过 Golang 称之为 fat pointer。通过这种方法能极大地减少堆内存的分配开销,使抽象的成本更低。
同时我们也注意到了,相比 Objective-C 这门古老的语言,Swift 等现代语言会把更多的优化和底层实现放在编译期进行,减少运行时所需的信息,这也是为什么大家感觉在 Swift 里做反射这类操作更难了。其实不是 Swift 不存储元信息,只是 Apple 不再希望开发者通过运行时的特性来完成业务逻辑,开发者越依赖运行时信息,未来底层的优化机会就会越少。同理,G 家的 Flutter 也不允许开发者在 Dart 里使用反射,因为会影响 tree shaking 优化。Swift ABI 现在已经稳定,我们仍然可以在开发阶段借助运行时信息来做一些调试用途的事情。在实现业务逻辑上,还是应该优先选择编译期的解决方案。